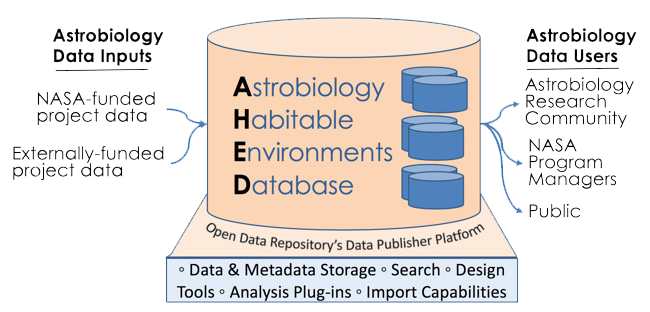
About AHED
The Astrobiology Habitable Environments Database (AHED) is a new data system being developed as a long-term, open-access repository for astrobiology data. AHED is intended to store user-contributed results from NASA or externally-funded research in astrobiology, and to encourage sharing and synergy within the astrobiology community.
A Repository for Astrobiology Datasets
This video demonstrates how simple is to Explore and Contribute to AHED.
Astrobiology is an interdisciplinary field that draws from disciplines including biology, chemistry, geology, physics, astronomy, computer, and planetary science to answer complex questions about the origin, evolution and distribution of life on Earth, and the search for life beyond Earth. The interdisciplinary nature of astrobiology presents some challenges to data management, integration, and analysis within AHED. In some disciplines (e.g., genomics), open databases thrive because the contributed products are fairly uniform and standardized (e.g., sequence data). In astrobiology, each investigation produces a unique set of data products; this makes it difficult to search across datasets to find similar data, or to combine results from separate investigations.
Challenge: Data Diversity and Interoperability
Astrobiology data is interdisciplinary (e.g. chemistry, biology, astrophysics, geology, planetary science) and data is heterogeneous:
- Multiple sources: field, lab, computational model, mission
- Multiple formats: proprietary instrument formats, images, observations, Microsoft Office documents, flat files, …
- Multiple measurements: water chemistry, gas composition, lipid characterization, XRD, XRF, isotopic composition, geological sample age, Raman spectroscopy, …
We are taking steps to ensure there is adequate metadata – both at the dataset and record levels – to facilitate search, integration, and analysis. At the dataset level, we are developing the AHED core template, a new metadata standard for describing astrobiology datasets, with detailed information about content, funding source, and scientific relevance, along with a set of topical keywords for characterizing datasets. The primary purpose of the AHED core template is to ensure that any database subscribing to the AHED metadata standard can be discovered and accessed through the AHED interface. The public (and semantic-web-based) definition of the AHED metadata standard will allow other platforms and software to curate datasets in a way that makes them discoverable and searchable by the AHED interface.
At the record level, we are encouraging users to provide more structured content and finer-grained metadata. In many user-contributed science data repositories, few restrictions are placed on the uploaded data format, and minimal or no record-level metadata is required; thus users are unburdened with respect to data preparation. The tradeoff is that deep integration and search across datasets is almost impossible without standardized structures and metadata. AHED users will be encouraged to use database authoring tools (supplied by the underlying platform – Open Data Repository’s (ODR) Data Publisher) plus a set of customizable astrobiology-specific templates to help structure their data and provide standardized metadata. To lower some of the barriers to database creation (e.g. time, expertise, technical experience) this library will provide a starting point for databases from a variety of sub-disciplines within astrobiology. Given the highly individualized nature of astrobiology datasets, users will not always be able to adopt existing templates; for this reason the ODR platform will permit customization and continuous curation and stewardship of the template library.
AHED aims to be a dynamic data system intended to allow researchers to discover, analyze, visualize, and use the data more readily than in a typical repository by leveraging a host of outside resources that can be integrated with the AHED data environment. These resources include open-source plugins, visualization libraries (e.g. D3.js, plotly.js), and an API interface for more in-depth data analysis using programming languages such as Python and R. The ultimate goal is to create a platform where data is readily available in a format that will facilitate active, onsite data cataloging, collaboration, discovery, and analysis for the growing field of astrobiology.